THATCamp Melbourne Pedagogy will be held at the University of Melbourne on 10th-11th October, 2014

Opening Session of THATCamp Melbourne 2011; people proposing sessions
See more photos from the day…(2011)

Opening Session of THATCamp Melbourne 2011; people proposing sessions
See more photos from the day…(2011)
ThatCamp Melbourne has come to a close but the knowledge shared and the great work produced shouldn’t stay ‘indoors’. In the spirit of linked open data please post your learnings, ruminations, reports, session links here so we can build on the ThatCamp experience. I have taken the liberty of kicking off with a clarion call of my own:
The Great PROV Data Challenge was an absolute ripper with all teams producing some brilliant work. We’d love to share your entries with the world so if anyone out there from The Kelly Gang, The Otway Rangers and The Grave Diggers would like to add a link to their hack in reply to this post we’d be really grateful!
History and archaeology are intimately connected with questions of what happened “where” and “when”, but traditional paper-based representations (eg. maps and timelines) are quite restrictive in what they can represent.
I’m interested in sharing skills and ideas with others on representing historical processes in space and time, by linking dynamic maps and animations with an interactive timeline. I’ll demonstrate the existing time-based capabilities of GoogleEarth and its authoring language KML – which have some exciting possibilities but also significant limitations. I’ll also introduce my own project, TemporalEarth, which pushes the technical boundaries to help discipline-experts author representations on topics in history, archaeology, geology and related disciplines. My initial prototype, SahulTime, provides some compelling ideas for how such methods could be put to use, and will provide a good basis for further discussion.
Ultimately, I hope to grow the project to become an explorable, comprehensive set of resources relating to Australia’s history on all timescales and spatial scales. So I wonder if anyone would be interested getting together to research/develop a visualisation covering their area of expertise. Possible examples: archaeological occupation sites, tribal boundaries, trading routes, Australian explorers, convict settlements, pastoral settlement, Aboriginal-European conflict, reserves/mission stations, the Gold Rush, urban development, railways, family histories, locational histories, artwork histories… basically anything that needs to be understood using both space and time.
I mentioned in my Bootcamp session outline that if people wanted to play along it would be good to have a web server stack installed. This sounds much scarier than it is is, and it really gives you the opportunity to start playing with a variety of web technologies in the safety of your own computer. So I was thinking that perhaps it would be good to have a ‘load my laptop’ session where folks can bring along their computers and other folks (hopefully not just me) can help them install web servers, databases, programming languages, editors, version control etc etc.
Anyone interested?
I propose we design a digital humanities unit from scratch. We should profile the staff and resources and the funding methods. We might even get cute and come up with a few fictional project descriptions that tell the story of how we came to be involved, how we thought through the designs and implementation and what sort of problems we encountered. The nice thing about doing this as a group design exercise is that the resulting account wont sound like one person winging about the problems they have experienced with a particular institution but instead may end up being quite a good descriptive document that will help us better define the actual on the ground processes of doing digital humanities.
Emerging research suggests that the Internet’s capacity to easily produce information has also led to data overload, undermining its deliberative potential.  With the advent of the National Broadband Network the ‘data deluge’ promises to intensify increasing the need for political information—in its various guises—to be delivered in much more meaningful ways.
We’ve partially developed one tool to be applied and extended we call ‘Poli-Fish’. It aggregates and rates the policies of registered Australian political parties (from their web sites) and displays them within various political spectrums. Through sliders, the user can explore a broad spectrum of policies along with the associated political parties. The prototype can be seen in action here:
http://disweb.dis.unimelb.edu.au/projects/ifish/poliFish/gFish.swf
The approach we are attempting is both innovative and unique because it combines the theoretical understandings of Politics and Media Studies with the technical proficiency of Humanities Computing, eDemocracy and Information Systems to expose important issues of online political information to critique in ways that were previously unavailable. This all raises various discussion points for the session on the dichotomy between the availability of government and other data sources and effective online deliberative design. The work may open up theoretical and technological pathways towards a more genuinely identifiable (and sustainable) online political engagement.
The Poli-Fish application is an instance of another project called iFish. The iFish project addresses the challenging problems of using online environments to offer advice relating to complex sets of data. The challenge is to maintain a user’s engagement in the system long enough to explore possible outcomes in a system that is not completely deterministic and offers no single right answer. Our particular research interest in using an engaging, affective interface to attract and maintain a person’s attention, whilst at the same time trying to keep their focus on the task presented. Hence we want to encourage exploration with mind on task. More information on the iFish project can be found here:
I understand that in the medium-term future all students undertaking a PhD through the Arts Faculty will be required to complete coursework in addition to their thesis. Calls have been made for suggestions for suitable courses.
My proposed session aims to discuss options for coursework in digital methods for the Arts and Humanities, and if possible set up collaborations to keep the project moving forward.
In the session we might begin to discuss which e-methods, which applications, and which skills are most appropriate to expose PhD students to, which pedagogical methods are best for this, how a curriculum might be structured, what outcomes we would want for our students, and so on.
My initial thinking on this is to offer two short courses….
1. A Critical Survey of Digital Methods in the Humanities and Social Sciences
The purpose of this short course is alert students to the range of electronic methods available to scholars for the purposes of document and data capture, collaboration and communication, data analysis, publishing and dissemination, data structure and enhancement, practice-led research, and research strategy and project management. Having completed this survey, students will be in a position to critically assess the value of particular digital methods for their own research work. The course may be offered largely online.
2. Applied Digital Methods in the Humanities and Social Sciences
The purpose of this short course is to enable students to gather practical expertise in the application of particular digital methods. It is anticipated that students will have previously completed “A Critical Survey of Digital Methods in the Humanities and Social Sciences†and that groups of interested students are clustering around particular applications. The course may be offered in intensive mode.
A few examples of the resources and tools we can draw on are here…
The NLA’s Trove Newspapers database is a magnificent resource for digital history, but it’s currently not very easy to do detailed analysis of content. I’ve been working on a few tools which make this easier and I’d be interested in giving a bit of a how-to session to explain them and the technologies they use and kick off a ‘what next’ discussion.
At the base of my tools is a screen-scraper which, in the absence of an official API, retrieves article information in machine-readable form. I’ve used this to create a harvester, which you can use to dump the results of your search to a CSV file for further analysis. It can also retrieve text and pdf versions of the articles. You can read more about the havester on my blog.
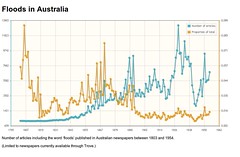 To provide a more quick and dirty picture of search results over time, I’ve created another little harvest tool that gets the number of results for each year and calculates what proportion this is of total articles (in Trove) for that year. I’ve used this to create a few interactive graphs as a demonstration.
To provide a more quick and dirty picture of search results over time, I’ve created another little harvest tool that gets the number of results for each year and calculates what proportion this is of total articles (in Trove) for that year. I’ve used this to create a few interactive graphs as a demonstration.
I’ve also used the scraper to create my own ‘unofficial’ Newspapers API on Google App Engine. I put this up to encourage people to have a play and think about the possibilities.
Depending on people’s interests I’m happy to walk through the development of these tools as well as describing how to use them.
But I’m also very interested in talking about further possibilities for analysing and visualising the results. I’ve been playing around with VoyeurTools, but I wonder what other ideas people have. What about comparisons with other data sources like Google’s ngrams? What other tools do we need? What other databases should we mine?
And lastly it would be good to talk about how we engage directly with the NLA to build a community of digital researchers and help encourage the development of tools like APIs.
Our project, Design and Art of Australia Online http://blogs.unsw.edu.au/daao/ is opening up contributions to the database to larger project community. Among other things we will developing communities around different spheres of scholarly research through social media style tools, conventions and practices. We will also be using some classic crowdsourcing techniques for datawashing and sub-editorial style projects. In other words, we will traversing a whole range of different cohorts with different needs and expectations of the site.
If we want lots of people to input quality data, we’ve been working hard on thinking about how to make the experience of using our site ‘rewarding’ ( as well as pleasurable). We’ve done a lot of work on user experience of data entry logical and pleasurable, but now we are turning our heads to the issues of community moderation system in a mixed cohort setting (has to generate value to academic, glam and ‘amateur’ research communities) and have been thinking about how to manage social reputation and activity systems ( ie badges etc).
We’ve been doing quite a bit work researching existing scholarly crowdsourcing projects, like the Zooniverse Science Projects http://www.zooniverse.org/home and of course the NLA’s newspaper projects etc. We’ve also been looking at badging reward systems like Foursquare etc. to see what productive ( if any) analogies could be made that produce any type of value for contributors.
Anyone interested in having a session on how you manage the affectual and reputational side of data? How to link permissions to reputations? How to give value to immaterial labour of online scholarly practices? Bluntly put, how to design ‘win- win’ into the front end of content hungry database? Practical focus: specifically looking at badging and reputation and permission systems.
Really happy to share or negotiate session with anyone who has similar problems to solve.
I’d like to propose a session that aims to produce (or failing that, define) a tool that will take in an Australian historical text and locate within this text all the mentions of people named in the Australia Dictionary of Biography (ADB).

Annotation in the Dictionary of Sydney
For each person referenced I would like to create a metadata record for the corresponding ADB entry in my own database and link this to an annotation record pointing to the mention in the text. Clearly it follows that if a given person is mentioned multiple times then multiple annotation records should be created all pointing to a single ADB metadata record.
I’d ideally like to be able to scan the text and have it OCRed into TEI first but I think that would be a bit ambitious. I wanted to at least to mention this as a reminder that ultimately the process should be input agnostic – one should as easily load up a newly created Word document as a scan of a historical manuscript.
I’ve hacked around over the years with offset markup using TEI source files in Heurist. We render TEI documents as XHTML using Cocoon, allow the user to select passages of text then create an annotation record which records the annotated string, the source text, the location within the text and an optional pointer to another record – which could be an ADB entry metadata record. The Dictionary of Sydney project in particular makes extensive use of this data structure with mentions of famous Sydneysiders within text entries pointing – via annotations – to person entity records. As often as not these then reference the ADB entry.
This tool would greatly simplify the current workflow of the Dictionary of Sydney and many of the projects I am involved with would also benefit from this process. The Dictionary of Sydney however relies on a large team of volunteers and a pretty active editorial team to create annotations “manuallyâ€. It would be great to have a semi automated procedure – possibly based around a bunch of clever XSL transforms and an XML feed from the ADB – that would enable me to connect a given research database with the ADB and indeed beyond (to paraphrase Buzz Lightyear).
I am interested in how to develop a tool that would be able to map the major concepts of a discipline and then to be able to link these concepts across disciplines.  The trick is to be able to map data from discourse – so that individual ideas about concepts, which are rich and varied, can be shown.  I have two (dream) versions of what this might result in. The first is a game of word association that allows someone to pick multiple words and results in a string of words that can be explained in more depth. The second is a more complex reckoning of this that might involve a sort of discourse analysis wherein the literature provides definitions of concepts and links between concepts.
An example might be Archival Science and the concept of the archive. There are many different ways this concept has been defined over the years – and this is closely related to culture and society. In the recent past there has been some very significant works published that talks about the archive – and with which other words such as power, responsibility, construction and so on might be relevant. Additionally, Australian concepts of the archive are quite a bit different to our American counterparts. Furthermore, people in other disciplines, even those as close as Library Science, or Knowledge Management, define the archive as something else again (or do they?).
I see this concept mapping as a research resource, as well as communications tool. I like the idea of people who are the current ‘big thinkers’ in the discipline adding their own definitions about concepts. I would also think it would be great to get some cool visualisations out of it.
Media provides the basis for much Humanities research. In Linguistics, field recordings are transcribed and then used as the proof for linguistic analysis. Access to media and provision of online versions of media and transcripts has become much easier with the release of HTML5 – no more streaming servers, no more flash. How can we use these technologies and what are the implications for the way we present the results of our research? I will be illustrating an example we have worked on recently, called EOPAS. Time-codes within media can be called from ordinary html pages so a dictionary can now have citation forms of headwords called from within large media files rather than having several thousand mp3 files on the server. This session will toss around ideas about using such media/text installations.
